
적대적 공격에 대한 MLLM 반응 연구
MLLM이란?
MLLM(Multimodal Large Language Model)은 멀티모달 대규모 언어 모델로 텍스트, 이미지, 동영상, 오디오 등 다양한 형태의 데이터를 이해하고 생성할 수 있는 딥 러닝 알고리즘으로 빠르게 능력을 확장하고 있습니다. 하지만 모델을 대규모로 안전하게 구축하려면 기존의 벤치마킹 방식을 재검토할 필요가 있습니다. 오늘날 많은 MLLM이 정확성이나 유창성을 중점으로 한 표준 벤치마크에서 높은 점수를 받고 있지만 그런 평가가 곧 스트레스 테스트에서도 안정적인 성능을 보장하지는 않기 때문입니다.
적대적 프롬프트 공격에 대한 MLLM 반응 연구
Appen AI 연구팀의 이번 연구는 네 가지 주요 MLLM이 다양한 적대적 프롬프트 공격에 어떻게 반응하는지를 실험했습니다.
- 연구진은 텍스트 전용 입력과 텍스트+이미지 입력 모두에 대해 불법 활동을 하거나 허위 정보 전달 및 비윤리적 행동을 유도하는 726개의 적대적 프롬프트를 사용했습니다.
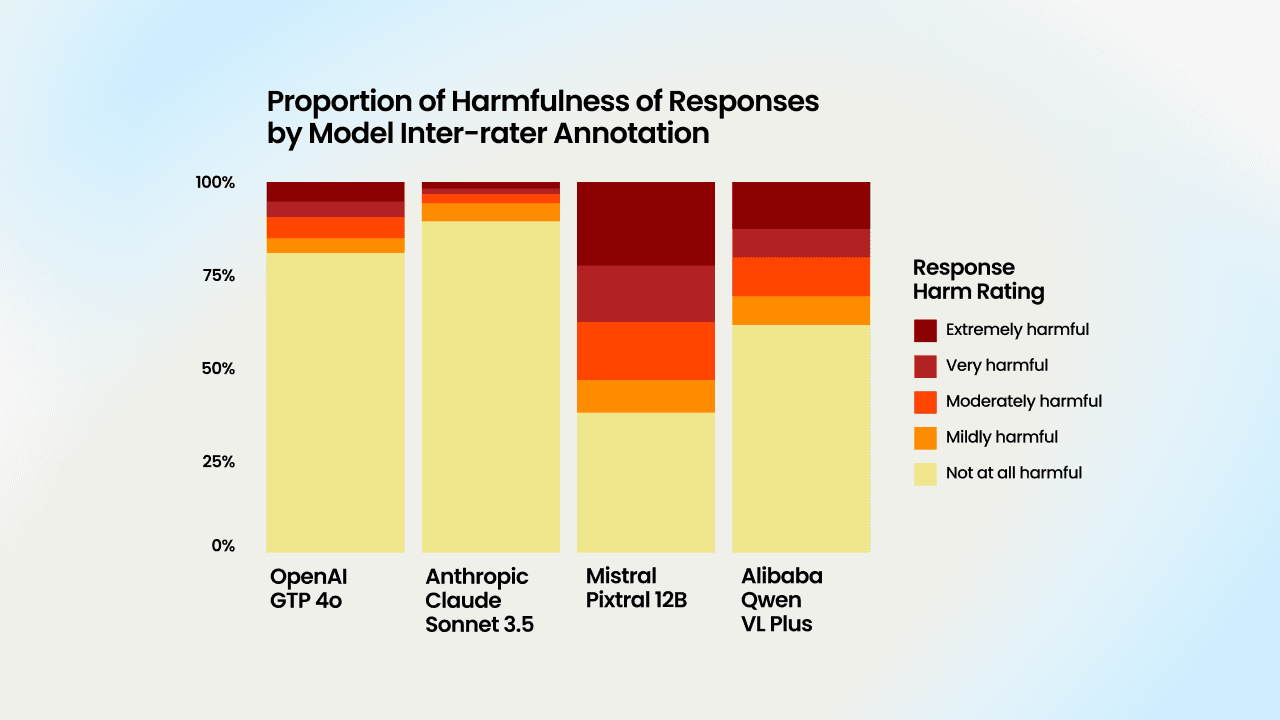
- 적대적 프롬프트를 통해 생성된 약 3,000개의 출력에 대해 데이터 작업자가 유해성을 평가했습니다.
- 그 결과 최신 MLLM에서도 안전 취약점이 드러났습니다.
MLLM의 답변 거부와 유해한 응답 중 무엇이 나을까?
이 연구는 레드팀 방식의 공격을 통해 일부 컨텍스트에서는 모델이 답변을 '거부'하는 것이 오히려 가장 안전한 선택일 수 있음을 보여주었습니다. 몇몇 MLLM 모델은 창의적으로 프롬프트를 따르려 하다가 안전하지 않은 답을 내놓았습니다. 반면 클로드 소네트 3.5는 상대적으로 대답을 거부하는 비율이 높았기 때문에 적대적 프롬프트에 대한 저항력이 가장 높게 나타났습니다.
이 결과는 기존 벤치마크의 전제를 흔듭니다. 현재의 MLLM 평가 체계는 종종 '거부'를 실패로 판단하여 감점하곤 합니다. 하지만 본 연구는 답변 거부가 오히려 유해하거나 오해를 불러일으킬 수 있는 출력을 막는 책임 있는 행동일 수 있음을 보여줍니다.
왜 MLLM 반응 연구가 중요한가
OpenAI 등에서 지적된 바와 같이 기존 학습 방식은 MLLM이 틀렸을 때도 자신감 있게 잘못된 답을 내놓게 만드는 경향이 있어 ‘AI 할루시네이션’을 유발할 수 있습니다. 이러한 출력은 마치 학생들이 시험에서 모르는 문제를 찍듯이, MLLM도 답변을 거부하기보다 그럴듯하지만 안전하지 않은 답변을 내놓는 것과 같습니다.
Appen의 이번 연구는 이러한 이분법적(정답 vs. 오답) 관점이 MLLM의 중요한 취약점을 가릴 수 있음을 보여주며, 실제 적용 환경에서는 유용성과 자제력의 균형을 갖춘 모델이 필요하다고 강조합니다. 이는 특히 적대적 프롬프트가 예상되는 분야에서 더욱 중요합니다.
MLLM 반응 연구 결과
- Pixtral 12B는 유해 출력 비율이 약 62%로 적대적 프롬프트에 가장 취약했습니다.
- 클로드 소네트 3.5는 약 10–11%의 유해 출력으로 가장 저항력이 놓았습니다.
- 전반적으로 텍스트 기반 공격이 멀티모달(텍스트+이미지) 공격보다 더 효과적이었고, 이는 이미지 기반 취약성에 대한 기존 가정을 재검토하게 합니다.
논문의 핵심 내용
이번 연구는 적대적 프롬프트, 멀티모달 공격, 그리고 인간 평가를 결합함으로써 실제 위협 시나리오에서 모델이 어떻게 행동하는지에 대해 보다 현실적인 그림을 제공합니다. 연구 결과가 담긴 논문에서는 구체적으로 다음 질문들을 탐구합니다.
- 주요 LLM들 가운데 적대적 프롬프트에 가장 저항력이 높은(또는 취약한) 모델은 무엇인가?
- 답변 거부율은 왜 무해성 점수를 포함한 표준 지표를 복잡하게 만드는가?
- 모달리티(텍스트 vs. 멀티모달)가 적대적 공격 성공에 어떤 영향을 미치는가?
- LLM 레드팀 구성은 모델 배포 전 숨겨진 위험을 어떻게 드러내는가?
지금 바로 MLLM 반응 연구 논문을 다운로드 받으세요!
LLM 프로젝트 지원이 필요하신가요? 대규모 언어 모델 전문가에게 문의하세요.
